VaxxStance@IberLEF 2021
The VaxxStance shared task is part of IberLEF 2021, the 3rd Workshop on Iberian Languages Evaluation Forum, co-located with the SEPLN Conference, which will be held in September 2021 in XXXXX, Spain.
Task Description
The aim of VaxxStance@IberLEF 2021 is to detect stance in social media on a very controversial and trendy topic, namely, the Antivaxxers movement, in two languages: Basque and Spanish. Following previous tasks (Mohammad et al. 2016, Taule et al. 2018, Cignarella et al. 2020), the aim is to determine whether a given tweet expresses an AGAINST, FAVOR or NEUTRAL (NONE) stance towards a previously defined topic.
In the two examples given below, the tweet on the left expresses a FAVOR stance towards vaccines whereas the one on the right conveys an AGAINST stance.
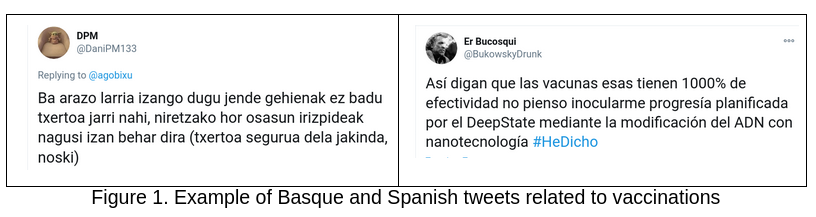
As the task contains tweets in two different languages, we would like to propose the following participation tracks for each language (Basque and Spanish):
- Close Track: Language-specific evaluation. Only the provided data for each of the languages is allowed. There are two evaluation settings:
- Textual: Only provided tweets in the target language can be used for development.
- Contextual: Text plus given Twitter-related information will be used by the participants. Contextual information refers to features related with user-based Twitter information: friends, retweets, etc. (Cignarella et al. 2020).
- Open Track: Participants can use any kind of data. The main objective consists of exploring data augmentation and knowledge transfer techniques for cross-lingual stance detection.
- Zero-shot Track: Texts (tweets) of the target language cannot be used for training. The main objective is to explore how to develop systems that do not have access to text in the target language, especially using Twitter-related information.
Additionally, and inspired by the recently held SardiStance 2020 shared task (Cignarella et al. 2020), the Close Track will include two evaluation settings per language: Textual and Contextual. Furthermore, the Open and Zero-shot tracks will include only one evaluation setting per language, one for Spanish and one for Basque.
Datasets
Train and test datasets are publicly available: VaxxStance 2021 Datasets
Citation: If you use the dataset please cite the following paper:
Rodrigo Agerri, Roberto Centeno, María Espinosa, Joseba Fernández de Landa, Álvaro Rodrigo (2021). VaxxStance@IberLEF 2021: Overview of the Task on Going Beyond Text in Cross-Lingual Stance Detection. Procesamiento del Lenguaje Natural, 67, pp 173-181.
Participation Rules
Participants can submit their systems to any of the tracks, but it will be compulsory to participate in both languages for the chosen track.
-
Example 1: If a team only takes part in the Close Track then that team would have to submit runs for both Basque and Spanish in each evaluation setting, Textual and Contextual.
-
Example 2: If a team articipates in the Zero-shot or Open tracks then runs must be submitted for both Basque and Spanish languages.
Furthermore, each team can submit two runs per evaluation setting and language. Thus, if a team participates in all 4 evaluation settings, then for each language it could submit 8 runs (2 Close-Textual, 2 Close-Contextual, 2 Open Track and 2 Zero-shot Track), namely, a total of 16 runs.
Runs Submission
Based on the participation rules above, participants must submit their runs in files following this file name nomenclature:
- team-name_track_language_run.csv
For example:
- DeepReading_Close-Textual-track_eu_01.csv means that this is the run number 01 submitted by the team DeepReading for the Close-textual track in Basque.
- DeepReading_Zero-Shot-track_es_02.csv: run number 02 by team DeepReading to the Zero-shot track for Spanish.
The content of the submission files will have the following format, namely, a CSV file containing 4 elements per row:
- tweet_id,user_id,text,label
This means that participants will need to add the Stance label prediction to the original eu_test.csv and es_test.csv sets distributed by the organizers, including the header.
For example:
- 1365339585023197189,97939627,Igandean txertoa jasoko dut,FAVOR
IMPORTANT: All runs by a team must be included in a zip archive with the name team-name_vaxxstance_runs.zip and submitted via Codalab by clicking on the button below:
Dates
The tentative schedule of the task is as follows:
- March 15: Training sets, evaluation script and annotation guidelines.
- April 30: Test sets released.
- May 24: Official date for submissions of system runs.
- May 28: Publication of official results and gold standard test annotations.
- June 15: Paper submission.
- June 22: Notification of acceptance (peer-reviews).
- June 30: Camera-ready paper.
- September: VaxxStance@IberLEF 2021.
Evaluation
Following previous work tasks already mentioned on stance detection, we will evaluate systems with the metric provided by the SemEval 2016 task on Stance Detection (Mohammad et al., 2016) which reports F1 macro-average score of two classes: FAVOR and AGAINST, although the NONE class is also represented in the test data:
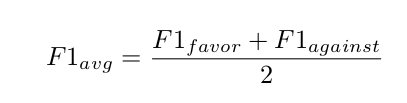
The official metric will evaluate systems taking into account both languages and topics, for each of the tracks and evaluation settings, namely, for each track we will provide a global score. This means that participants should aim to perform equally well across languages. Furthermore, we will provide individual scores per language for each track (and for each evaluation setting in the Close Track).
Therefore, for official results of every track and evaluation setting participants should include predictions for both languages (Basque and Spanish).
Baselines
We provide two baselines using the training set:
- Textual: based on SVM with TF-IDF for document representation with grid search. [Get textual baseline]
- Social: using only social network features (user and tweet information). [Get social baseline]
| Basque | Spanish | |||
|---|---|---|---|---|
| System | AGAINST | FAVOR | AGAINST | FAVOR |
| Textual | 64.92 | 66.76 | 69.46 | 80.37 |
| Social | 46.30 | 39.30 | 82.20 | 72.40 |
Results
Here are the official results per track. We will shortly publish an overall ranking and the baseline results.
Close Track (Textual and Contextual)
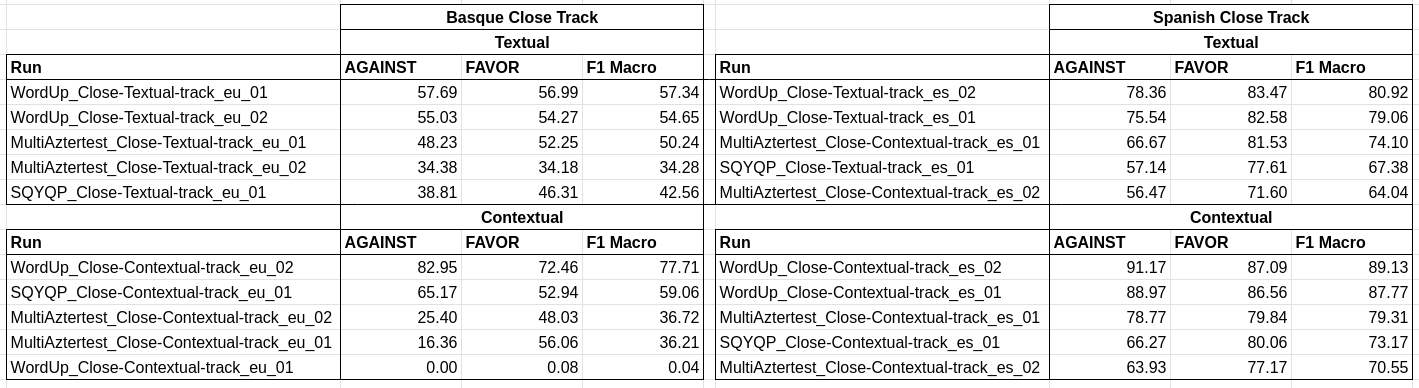
Open and Zero-shot Tracks

References
Alessandra Teresa Cignarella, Mirko Lai, Cristina Bosco, Viviana Patti, and Paolo Rosso. 2020. Overview of the EVALITA 2020 Task on Stance Detection in Italian Tweets (SardiStance). In Valerio Basile, Danilo Croce, Maria Di Maro, and Lucia C. Passaro, editors, EVALITA 2020. CEUR-WS.org.
María S. Espinosa, Rodrigo Agerri, Alvaro Rodrigo and Roberto Centeno.DeepReading@SardiStance:Combining Textual, Social and Emotional Features. Proceedings of the Seventh Evaluation Campaign of Natural Language Processing and Speech Tools for Italian (EVALITA 2020).
Joulin, A., Grave, E., Bojanowski, P., Mikolov, T., 2017. Bag of tricks for efficient text classification. In EACL 2017.
Lai, M., Cignarella, A., Hernandez Farias, D., Bosco, C., Patti, V., Rosso, P., 2020. Multilingual Stance Detection in Social Media Political Debates. In Computer Speech & Language.
Mohammad, S., Kiritchenko, S., Sobhani, P., Zhu, X., & Cherry, C. (2016, June). Semeval-2016 task 6: Detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016) (pp. 31-41).
Taulé, M., Rangel, F., Martí, M.A., Rosso, P., 2018. Overview of the task on multimodal stance detection in tweets on catalan 1oct referendum. In IberEval 2018.
Zotova, E., Agerri, R., Nuñez, M., Rigau, G., 2020. Multilingual Stance Detection in Tweets: The Catalonia Independence Corpus. In LREC 2020.
Zotova, E. Agerri, R., Rigau, G, 2021. Semi-automatic generation of multilingual datasets for stance detection in Twitter. Expert Systems with Applications, 170 (2021).[Preprint] ()https://doi.org/10.1016/j.eswa.2020.114547
Organizers
- Rodrigo Agerri, HiTZ Center - Ixa, University of the Basque Country UPV/EHU.
- Roberto Centeno, UNED Research Group in Natural Language Processing and Information Retrieval, UNED.
- María Espinosa, UNED Research Group in Natural Language Processing and Information Retrieval, UNED.
- Joseba Fernandez de Landa, HiTZ Center - Ixa, University of the Basque Country UPV/EHU.
- Alvaro Rodrigo, UNED Research Group in Natural Language Processing and Information Retrieval, UNED.
Contact
Questions to the organizers about the shared task will be managed through the Discussion Website.